I have to apologise for not being more social with the Discord evenings.
I’ve started toying around with implementing the algorithm in the following paper in an FPGA:
Mostly because I’ve never had the need/opertunity to do much with DSP and FPGAs.
I understand that most won’t have access to IEEE, nor will have much interest in power system synchrophasor estimation. Which is fair enough, but there’s some interesting challenges in the algorithm.
The basic constructs of the algorithm are as follows:
- Collect typically 1.5 line cycles of samples with GPS timestamp
- Perform two vector multiplication and accumulate operations on the sample set with a set of coefficients that correspond to the predicted line frequency.
- Calculate the arctan of the output of the previous step to get the phase.
- Calculate the frequency from the difference in phase between the previous cycle and the current cycle.
- This cycle is repeated to update the predicted frequency until it converges, or a max number of iterations are achieved.
This isn’t a difficult algorithm to implement in software (hence it’s been quite popular), however it needs quite a bit of processing grunt to achieve realtime (think RPi) which is difficult with the requirement for microsecond timestamping. If it can be done in a smallish FPGA, it will significantly reduce the cost and complexity of current implementations I’ve read and been involved in previously.
So the first part, hooking up an ADC and streaming into a cyclic block ram buffer is pretty straightforward.
The second part, the vector multiplication with a varying set of coefficients is the first challenge. This needs around 3-400 multiplication/accumulate operations per update, with a unique set of coefficients for each frequency interval. E.g. 50.01Hz, 50.02Hz etc. So bounding to 45 to 55 Hz with 0.01Hz resolution, that’s 1000 coefficient sets.
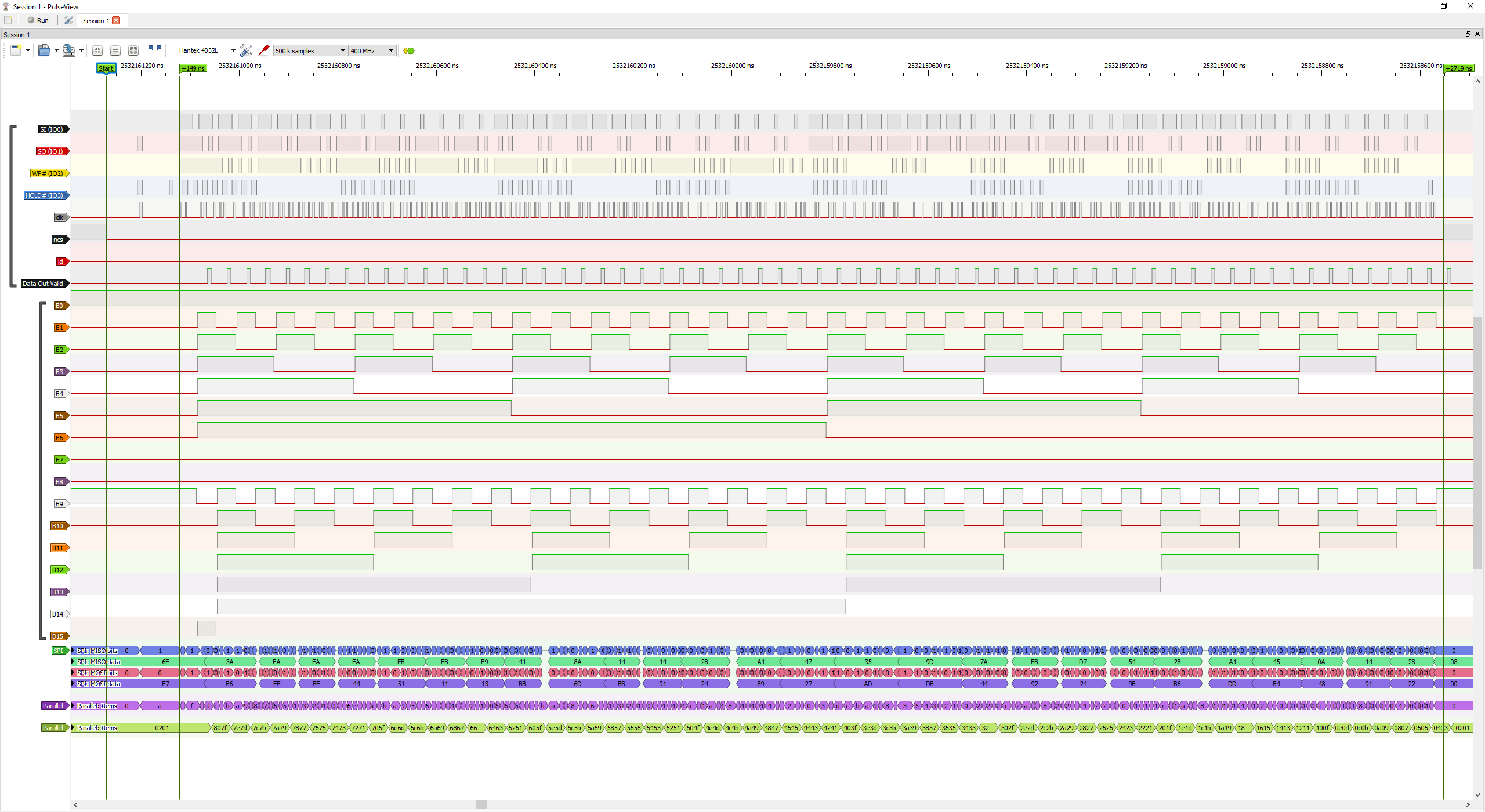
That works out to be around a couple of MB of constants, so it’s clearly going to be external to the FPGA. I’ve toyed around with a few ideas and settled on using SPI Flash memories that support 100MHz Quad-SPI mode, as they’re dirt cheap (used in ESP8266 modules), and can approach 50MB/s read rate using the constant Q-SPI read mode.
I have a controller built that I’ll put into github once it’s cleaned up a bit. So far I have it working up to about 50MHz SPI clock, but signal integrity and a fairly naive implementation is holding it back. Need to design a proper PCB and adjust the controller design to put the input registers into the IO blocks to reduce the propagation delay. This could be quite a useful little block in itself for other projects.
For those that haven’t used FPGA’s much, one of the really nice things is the ability to route signals to any pin for in system programming/testing. In the pic below I have an Ardunio’s SPI bus hooked up to a few other pins on the FPGA, and a project that just links the Ardunio up to the SPI flash for programming it.
The rest of the processing pipeline I think should be doable, so I think it’s time to make a PCB for the project.
Ok that’s more than enough for one post…